教師あり学習から予測分析へ~データサイエンスを支える人工知能(AI)技術~ | 第一線で活躍するオープンソースエキスパートが綴るスペシャルコラム。
教師あり学習から予測分析へ~データサイエンスを支える人工知能(AI)技術~ | 第一線で活躍するオープンソースエキスパートが綴るスペシャルコラム。




[2016年09月21日 ]
株式会社KSKアナリティクス
データアナリスト 足立 悠
前回はデータ分析において重要な「機械学習」の考え方をご紹介しました。もう一度復習しておくと、機械学習とは「機械にデータを解析させ、データに潜む規則性(ルール)やパターンを発見、アルゴリズムを発展させていくプロセス」を指します。
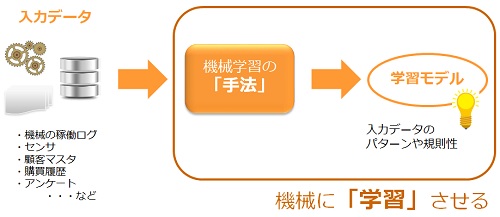
そして、機械学習には次の4種類の手法が良く使われています。
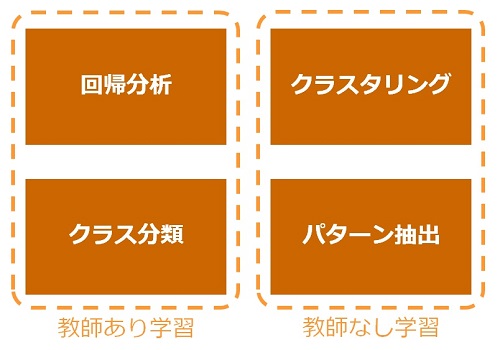
今回は上図左下の「クラス分類」を採り上げて、教師あり学習についてご紹介します。ここで、機械の故障予測について考えてみます。

機械には電圧・圧力など各種センサが取り付けられており、時々刻々とセンサ値そして状態(正常/故障)がデータとして蓄積されているものとします。
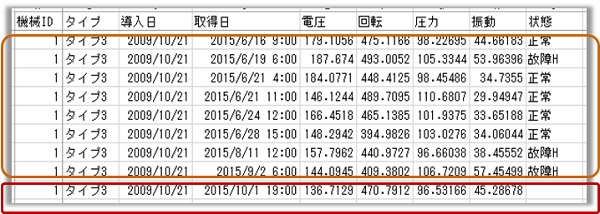
上図の茶色枠で囲っているデータをご覧ください。「状態」列に何かしらの値が入っています。予測対象となる値(正解となる値)を持っているため、このデータを教師ありデータと呼びます。教師あり学習とは「教師ありデータを使って、データに潜むパターンや規則性の集合体であるモデルを作成するプロセス」を指します。
次に、上図の赤枠で囲っているデータをご覧ください。状態列に値がありません。このデータを作成したモデルに適用すれば、状態列の値を予測することができます。以上のフローを図示すると次のようになります。
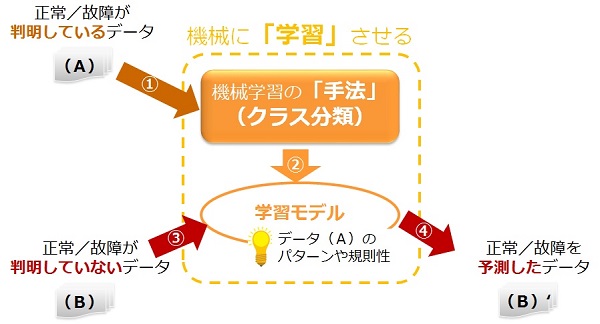
以上が教師あり学習と予測分析の概要です。教師あり学習を行うアルゴリズムには次のようなものがあります。
・決定木
・k近傍法
・ナイーブベイズ
・ニューラルネットワーク
・サポートベクタマシン
・ディープニューラルネットワーク(ディープラーニング)※こちらの詳細は後日
※決定木アルゴリズムは説明しやすいモデルを作成します。
今回ご紹介した教師あり学習・予測分析を実装できるオープンソース・無料のデータ分析ソフトはこちら。
・RapidMiner:プログラミング不要、GUI操作で誰でも簡単に分析できる。
・NYSOL:コマンドを記述して高速に分析できる。データ加工処理が得意。
・Revolution R:R言語でスケーラブルなハイパフォーマンス分析環境を構築できる。
ソフトは各リンク先から入手できますので、ぜひお試しください!
次回は「教師なし学習」とは?何に使えるのか、をご紹介します。

大手電機メーカーでエンジニア、事業会社でデータ分析者を経てKSKアナリティクスへ入社。社内のデータ活用推進者としてマーケティング戦略、業務改善に関するデータ分析業務に携わる。テキストマイニング、レコメンデーション手法が得意。
また、大学院(博士後期課程)にて人の行動データを使った予兆検出(複雑ネットワーク、トピックモデル)に関する研究に従事。

2022-07-28(木)15:00 - 16:00 「【サービス事業者向け】中小企業が狙われた、サプライチェーン攻撃の手口を解説 ~サイバー攻撃の被害に遭う中小企業の3つの共通点と、その対策~」 と題したウェビナーが開催されました。 皆様のご参加、誠にありがとうございました。 当日の資料は以下から無料でご覧いただけます。 ご興味のある企業さま、ぜひご覧ください。
「Apache Hadoop(アパッチ ハドゥープ)」とは、 ビッグデータを複数のマシンに分散して処理できる、オープンソースのプラットフォームである。


2021/03/04 セキュリティDAYS Keyspider資料
本資料を見るには次の画面でアンケートに回答していただく必要があります。


Analytics News ACCESS RANKING









