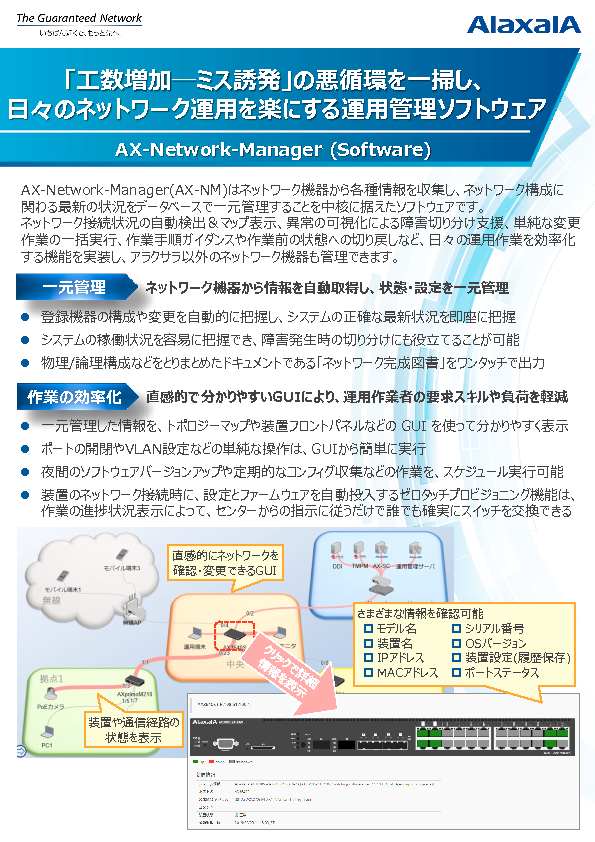
CLOSE UP コラム | いまいち分からない、ビッグデータの定義。
CLOSE UP コラム | いまいち分からない、ビッグデータの定義。




2017年03月27日
オープンソース活用研究所 所長 寺田雄一
「ビッグデータ」という言葉自体はすっかりビジネスの現場に浸透したが、実は、その定義はあいまいのままだ。世界のデータの90%は過去2年間で生成されたとも言われ、これまでの常識を超えたビッグデータは、その定義も想定外にある。現状では、ビッグデータの基本とも言われるVolume(量が多い)、Variety(多様である)、Velocity(スピードが速い)を兼ね備えた、いわば、未知なるデータの世界に対する総称を「ビッグデータ」と呼んでいる印象が強い。いまこの瞬間も加速度的に増え続けるビッグデータの定義について、本稿では、さまざまな側面から考察する。
総務省による2012年度版「情報通信白書」では、ビッグデータを「事業に役立つ知見を導き出すためのデータ」としている。しかしこの説明では、指し示す対象が広すぎて定義と呼ぶにはほど遠い。
なぜ「ビッグデータ」を定義づけることが難しいのか? 「ビッグデータビジネスの時代」(翔泳社)など、ビッグデータ関連の著作がある野村総合研究所 ICT/メディア産業コンサルティング部の鈴木良介氏によると、ビッグデータという言葉は「明確な定義をする必要性が薄い」のだと言う。
鈴木氏によると、注目が集まった当初、「ビッグデータ」はITベンダーが注目するトレンドだった。すなわち、RDB(Relational Database:リレーショナルデータベース)やDWH(Data Warehouse:データウェアハウス)といった既存システムで扱うことが困難である量と種類と速さをもつビッグデータを、「どのような方法で処理するのか」という部分に焦点が置かれたのである。しかし2017年現在では、ビッグデータは経営者が注目する存在となっている。すなわち、「自社ビジネスにどのように活用できるのか?」という部分がビッグデータの刮目に値する部分なのだという。企業ごとに活用方法が異なるビッグデータを、ひとくくりに定義するのは難しいというわけである。
そもそもビッグデータという言葉がはじめに登場したのは、1998年に遡る。その後、2008年に科学誌「ネイチャー」で“Big Data"の特集が組まれたり、2010年に英国の経済誌「エコノミスト」が“Data, data everywhere"という特集を組んだことなどが大きなきっかけになった。
このトレンドを加速させたのは、クラウド、モバイル、ソーシャル、IoTである。ビッグデータは、これら21世紀のITを牽引するトレンドと密接に絡み合いながら急成長している。クラウドは“ビッグデータのゆりかご"として膨大なデータを抱える場所となり、モバイルやソーシャルはビッグデータの生成される場所と頻度を増やした。センサーデータ中心のIoTはそうした流れの延長線上で現在、大きく飛躍している。
また既存の大量データとビッグデータの違いは、Variety、データの多様性にある。RDBに保存される構造化データは文字列や数値だけで構成されているが、ビッグデータでは画像や動画、テキスト、PDF、音声、メール、ログ、XMLなどの非構造化データや半構造化データも含む。さらに前述のように経営者が注目するようになってからというもの、構造化、非構造化に関わらず、ビジネス活用の幅を拡げることにつながるあらゆるデータを“ビッグデータ"と呼ぶ傾向もある。
IT業界のみならず、ビジネス業界全般に広まったビッグデータという言葉は、既存のビジネスの置き換えではなく、「これまでは不可能だった新規ビジネスに挑戦できる可能性を秘めたデータ」と、ゆるく定義することもできる。ビッグデータ活用という視点に立てば、「自分たちが本当にやりたいことは何なのか?」、「そのためにデータというリソースをどう使えばいいのか?」という戦略こそが重要になる。言い換えれば、その企業ならではのビッグデータ活用が、ビッグデータの定義を塗り替えるのかもしれない。
下記サイトからの要約。
http://e-words.jp/w/%E3%83%93%E3%83%83%E3%82%B0%E3%83%87%E3%83%BC%E3%82%BF.html
http://bizmakoto.jp/makoto/articles/1406/09/news016.html
https://japan.zdnet.com/article/35061220/

1993年、株式会社野村総合研究所(NRI)入社。 インフラ系エンジニア、ITアーキテクトとして、証券会社基幹系システム、証券オンライントレードシステム、損保代理店システム、大手流通業基幹系システムなど、大規模システムのアーキテクチャ設計、基盤構築に従事。 2003年、NRI社内に、オープンソースの専門組織の設立を企画、10月に日本初となるオープンソース・ソリューションセンター設立。 2006年、社内ベンチャー制度にて、オープンソース・ワンストップサービス 「OpenStandia(オープンスタンディア)」事業を開始。オープンソースを活用した、企業情報ポータル、情報分析、シングルサインオン、統合ID管理、ドキュメント管理、統合業務システム(ERP)などの事業を次々と展開。 オープンソースビジネス推進協議会(OBCI),OpenAMコンソーシアムなどの業界団体も設立。同会の理事、会長や、NPO法人日本ADempiereの理事などを歴任。 2013年、NRIを退社し、株式会社オープンソース活用研究所を設立。

2022-07-28(木)15:00 - 16:00 「【サービス事業者向け】中小企業が狙われた、サプライチェーン攻撃の手口を解説 ~サイバー攻撃の被害に遭う中小企業の3つの共通点と、その対策~」 と題したウェビナーが開催されました。 皆様のご参加、誠にありがとうございました。 当日の資料は以下から無料でご覧いただけます。 ご興味のある企業さま、ぜひご覧ください。
クラスター分析 (Cluster analysis)とは、異なる性質のものが混ざりあっている集合体から互いに似たものを集めてグループ(Cluster)を作ることで対象を分析する手法。客観的な基準に従った科学的な分類が可能となるため、マーケティングリサーチなどでよく用いられる。
「主成分分析」とは、ビッグデータをはじめとした多変量データを統合し新たな総合指標を作り出し、多くの変数にウェイトをつけて少数の合成変数を作る統計手法である。ビッグデータ分析の現場などにおいて、多変量の情報をできるだけ損なわずに低次元空間に縮約する。多変量データを二次元や三次元データに縮約することで、データ全体の視覚化が可能となり、データのもつ情報を解釈しやすくなる。

2021/03/04 セキュリティDAYS Keyspider資料
本資料を見るには次の画面でアンケートに回答していただく必要があります。


Analytics News ACCESS RANKING