フェイスブック、ディープラーニングを活用したテキスト分類ソフトウェアをオープンソースで公開。
フェイスブック、ディープラーニングを活用したテキスト分類ソフトウェアをオープンソースで公開。
 2025.4.24 [ THU ]
2025.4.24 [ THU ]


TOPICS 2016年9月10日 10:00

Facebook(フェイスブック)の人工知能研究所が開発したテキスト分類ソフトウェアfastTextが、オープンソース化された。今後、世界中の開発者が、そのライブラリを使ったシステムを実装できることになる。
何十億ものコンテンツがシェアされているフェイスブックでは、その膨大な量とペースに漏れなく遅れなく対応するために、さまざまなツールを駆使してテキストを分類している。多層ニューラルネットワークのような従来的な方法は正確だが、訓練に時間を要する。分類に正確さと容易さの両方をもたらすために開発されたのが、ディープラーニング技術を存分に活用したfastTextである。
fastTextは従来のディープラーニング(多層ニューラルネットワーク)よりも速い。実行時間が「秒」の単位なのは、fastTextだけである。
フェイスブックによると、ディープラーニングを活用したfastTextは英語だけでなくドイツ語やスペイン語、フランス語、チェコ語などにも対応し、通常のマルチコアのCPUを使って10億語を10分弱で学習できる。また、50万のセンテンスを30万あまりのカテゴリーに5分弱で分類できるという。
以上、下記URLからの要約。
http://jp.techcrunch.com/2016/08/19/20160818facebooks-artificial-intelligence-research-lab-releases-open-source-fasttext-on-github/
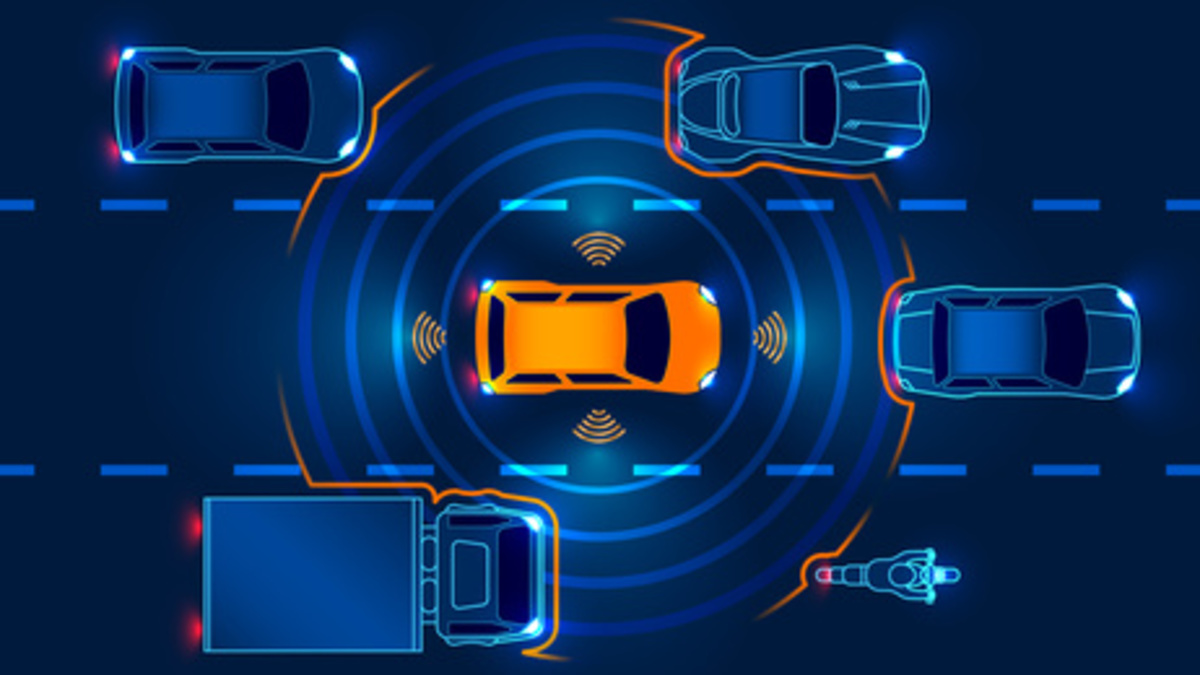
Dynatrace社が「IoT消費者信頼感報告:エンタープライズクラウド監視の課題」と題するレポートを発表し、消費者はIoTデバイスに対してさまざまな潜在的リスクを感じていることが分かった。 自家用車IoTに対する懸念 消費者の懸念の中で最も明白なのは自家用車であった。 調査対象者の中で85%が...

2021/03/04 セキュリティDAYS Keyspider資料
本資料を見るには次の画面でアンケートに回答していただく必要があります。


Analytics News ACCESS RANKING








