全ての人がビッグデータを活用できる「NYSOL」 | 第一線で活躍するオープンソースエキスパートが綴るスペシャルコラム。
全ての人がビッグデータを活用できる「NYSOL」 | 第一線で活躍するオープンソースエキスパートが綴るスペシャルコラム。




[2016年08月02日 ]
株式会社KSKアナリティクス
NYSOL(「にそる」と読みます。)とは、大規模データの解析に関する様々な大学やプロジェクトでの研究成果を、広く産業界に還元する目的で構築されたソフトウェアツールの総称およびそのプロジェクト活動です。
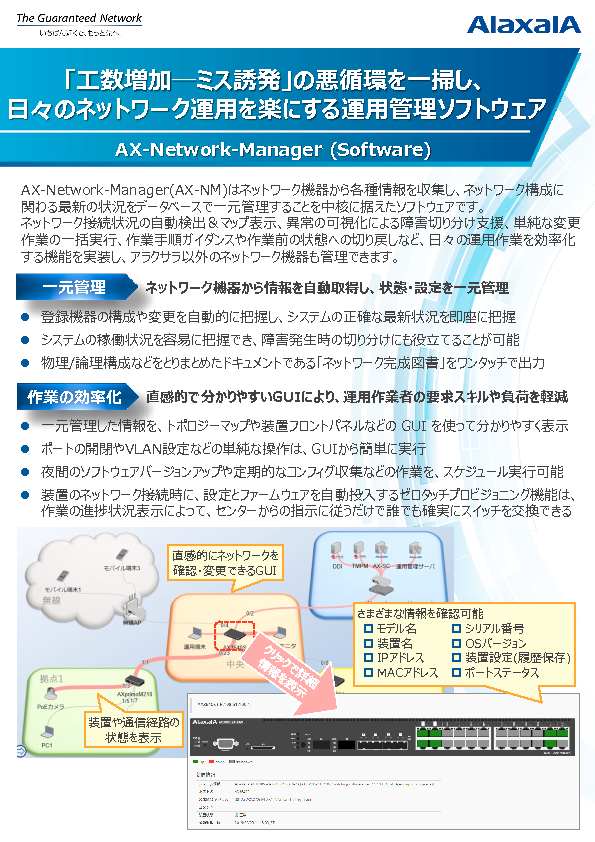
データ分析では、分析の手法やアルゴリズムにフォーカスしがちですが、実は一番時間と労力を割くのは、分析アルゴリズムに投入するためのデータを加工する「前処理」と呼ばれるプロセスです。
この前処理(データ加工)は、データ分析のプロセスの中で8割以上も占めています。
NYSOLには「頻出パターンマイニング」や「データマイニング・機械学習」「テキストマイニング」「可視化」などさまざまなパッケージがありますが、今回ご紹介するのは前処理(データ加工)を簡単に行えるNYSOLのMコマンドです。

このMコマンドを用いることで、一般的にHadoopなどで分散処理が必要とされる数百GB〜TB(数千万件〜数億件程度)の大規模なデータでも一台のサーバーで処理することが可能です。

一般的に前処理(データ加工)では、ETLツールやプログラムが使用されることが多いですが、よく発生する問題としてはマシンのメモリ不足により、データを処理出来ないことが発生します。
また、大規模なデータを処理する場合、メモリ上では処理出来なくなりハードディスクで処理する場合もありますが、この際に処理スピードが極端に落ちることによって、処理が終わらないといった状況が発生することもあります。
以下の図は1億件(10GB)のデータに対して、RやPostgreSQL、NYSOLのMコマンドで前処理を実施し、ベンチマークをとった際の結果です。
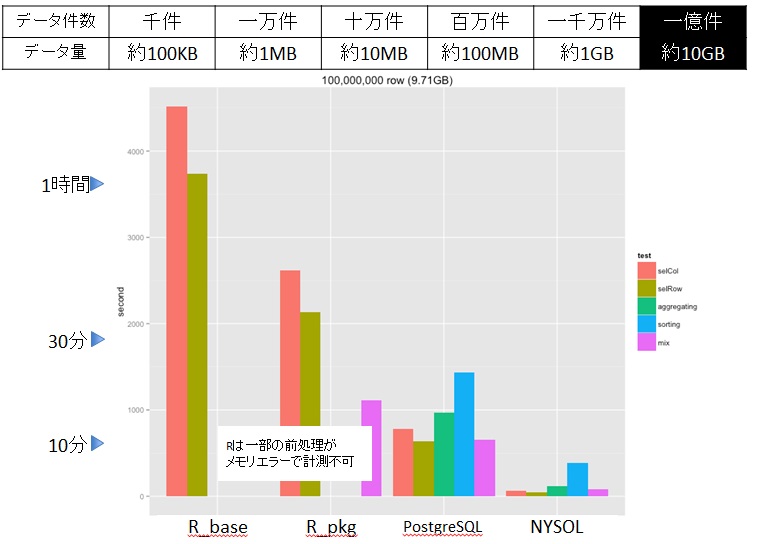
棒グラフの左2つはRですが、一部の前処理がメモリ不足で処理が出来なくなりました。また、PostgreSQLは処理結果が得られるまでに10分以上かかります。さらにデータが増えると処理時間に顕著な差があらわれます。実際の前処理(データ加工)では複数回のコマンドが実行され、長期かつチームで行われることが普通ですので、単純計算でNYSOLでは1か月で終わるプロジェクトが他では何年もかかる計算になります。また、そもそもデータ加工が出来ない状況もあるかもしれません。
NYSOLのMコマンドはこのデータを処理出来ないと処理が終わらないの2つの問題を同時に解決します。しかも1台のマシンで充分のため複数台のマシンを用意するコストも削減します。

さらにNYSOLのMコマンドはドキュメントが充実していますので、簡単に習熟することが出来ます。また、Mコマンドの簡単なチュートリアルを使い方ページに記載していますので、こちらから段階的に実施して頂くことをお勧めします。その前に、NYSOLをインストールされていない方はまずはインストールページをご覧下さい。
何かお困りの際はコミュニティページへご質問を投稿して頂くことも可能です。また、講師付きかつテキストをご提供するトレーニングもございます。また、本格的にビジネスで運用される際はサポートやコンサルティングもご提供しておりますので、お気軽にご相談下さい。

KSKアナリティクスのビジョンは、
優れたアナリティクスの「オープンソース・ソフトウェア」と、
現場と協働する「アナリティクス・サービス」で、
誰もが当たり前にデータを分析・活用できる社会を作ることです。

2022-07-28(木)15:00 - 16:00 「【サービス事業者向け】中小企業が狙われた、サプライチェーン攻撃の手口を解説 ~サイバー攻撃の被害に遭う中小企業の3つの共通点と、その対策~」 と題したウェビナーが開催されました。 皆様のご参加、誠にありがとうございました。 当日の資料は以下から無料でご覧いただけます。 ご興味のある企業さま、ぜひご覧ください。
「ERP(Enterprise Resource Planning)」とは、企業における資源(人材、資金、設備、資材、情報など)を一元的に管理し、経営を支援するための手法。その手法のために利用される業務横断型ソフトウェアパッケージは、「ERPパッケージ」「統合基幹業務システム」「統合業務パッケージ」などと呼ばれている。
「テキストマイニング」とは、自然言語解析などの手法を用いて、大量のテキストデータから付加価値の高い「知見」を探し出す技術である。人間が使用する一般的な文章データについて、文章を単語レベルに分割し解析することで「有益な情報」や「傾向」を取り出すことを目的とする。


2021/03/04 セキュリティDAYS Keyspider資料
本資料を見るには次の画面でアンケートに回答していただく必要があります。


Analytics News ACCESS RANKING