ディープラーニングとは?(前編)~データサイエンスを支える人工知能(AI)技術~ | 第一線で活躍するオープンソースエキスパートが綴るスペシャルコラム。
ディープラーニングとは?(前編)~データサイエンスを支える人工知能(AI)技術~ | 第一線で活躍するオープンソースエキスパートが綴るスペシャルコラム。




[2016年12月21日 ]
株式会社KSKアナリティクス
データアナリスト 足立 悠
前回までは、「教師あり機械学習」と「教師なし機械学習」の考え方と活用イメージをご紹介しました。少し間が空いてしまったので再度復習しておくと、機械学習とは「機械にデータを解析させ、データに潜む規則性(ルール)やパターンを発見、アルゴリズムを発展させていくプロセス」を指します。
そして、機械学習には次の4種類の手法が良く使われています。
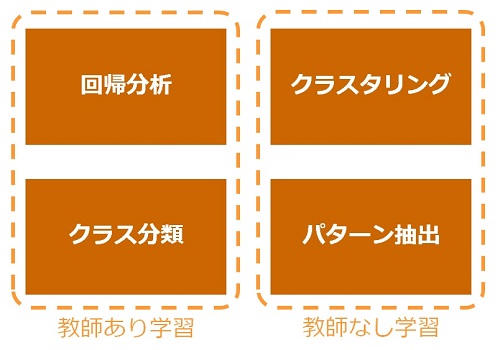
教師あり学習は、正解(目的変数、ラベル)を持つデータを使って学習モデルを作成する予測型の学習です。教師なし学習は、正解を持たないデータを使って学習モデルを作成する発見型の学習です。今回は、教師あり・予測型の学習に属する(教師なし学習も可)「ディープラーニング」をご紹介します。
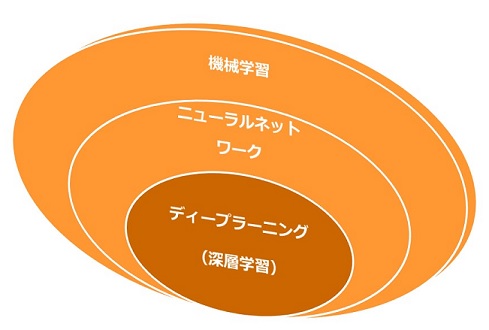
ディープラーニングは今や新聞の一面、ニュースのキーワードに挙がるほど社会に浸透しています。身近な代表例としては、ソフトバンク社のロボット「Pepper」、マイクロソフト社の女子高生AIボット「りんな」、Google社を始め自動車メーカーも研究開発を進めている「自動運転」などが挙げられます。では、この「ディープラーニング」とはそもそも何なのでしょうか? ディープラーニングを理解するためにはまず、「ニューラルネットワーク」について知る必要があります。ニューラルネットワークはディープラーニングのベースとなるアルゴリズムです。更に言うなら、ニューラルネットワークはパーセプトロンの考え方がベースとなっているのですが、ここでは扱わないことにします。ニューラルネットワーク、ディープラーニングの位置付けは以下のとおりです。ディープラーニングはニューラルネットワークの発展系なので、機械学習の一部に位置付けられますが、見方を変えれば新しいアルゴリズムであると捉えることもできます。
ニューラルネットワークは教師あり学習アルゴリズムの一つで、数値データを使った回帰・分類を行い予測できるものです。例えば、機械・設備の故障予測を例に考えてみましょう。学習モデルのイメージは以下のとおりです。
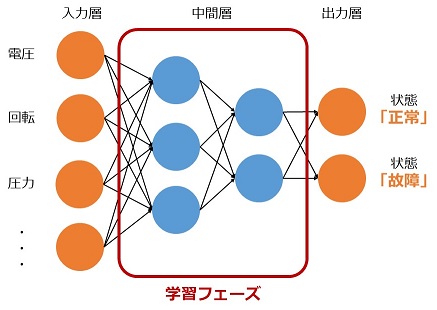
図の○はデータを格納する箱、→はデータを渡す道だと思ってください。
一番左端の○は、入力データを格納する「入力層」です。各○には電圧センサ値、回転センサ値、・・・、など数値データが入ります。そして、入力層のデータをそのすぐ右の「中間層」へ重みを付けて渡します。中間層では受け取ったデータを「活性化関数」を使って変換します。例えばシグモイド関数などが用いられます。その次も同様にしてデータを渡し変換し、最終的に一番右の「出力層」で計算結果を出力します。この一連の処理を「順伝播」と呼びます。
元データは正解(正常/故障)を持っているため、出力層の計算結果と比較し誤差を計算し、誤差を小さくするよう学習を続けます。この処理を「逆伝播」と呼びます。誤差の閾値を設けるか、指定した計算回数分だけ学習を継続します。
以上がニューラルネットワークのアルゴリズムの概要です。このアルゴリズムは人間の脳の構造を模して考案されたものであり、複雑な問題に対応できる画期的な手法として期待されました。しかし、計算量の多さや計算時間の長さがネックとなり、当時のマシンスペックでは現実に使える手法ではありませんでした。また、中間層を増やして計算を複雑にすると精度は向上するが学習が適切に行われないなどの欠点もありました。その後、2006年にトロント大学のHinton博士が新たなアルゴリズムを考案するまで、ニューラルネットワークは日の目を見ない状態だったのです。
今回はここまで。今回ご紹介した「ニューラルネットワーク」は以下のソフトウェアで実装可能です。ぜひお試しください!
・RapidMiner:プログラミング不要、GUI操作で誰でも簡単に分析できる。
・Revolution R:R言語でスケーラブルなハイパフォーマンス分析環境を構築できる。
次回はいよいよディープラーニングについてご紹介します。

大手電機メーカーでエンジニア、事業会社でデータ分析者を経てKSKアナリティクスへ入社。社内のデータ活用推進者としてマーケティング戦略、業務改善に関するデータ分析業務に携わる。テキストマイニング、レコメンデーション手法が得意。
また、大学院(博士後期課程)にて人の行動データを使った予兆検出(複雑ネットワーク、トピックモデル)に関する研究に従事。

2022-07-28(木)15:00 - 16:00 「【サービス事業者向け】中小企業が狙われた、サプライチェーン攻撃の手口を解説 ~サイバー攻撃の被害に遭う中小企業の3つの共通点と、その対策~」 と題したウェビナーが開催されました。 皆様のご参加、誠にありがとうございました。 当日の資料は以下から無料でご覧いただけます。 ご興味のある企業さま、ぜひご覧ください。
「主成分分析」とは、ビッグデータをはじめとした多変量データを統合し新たな総合指標を作り出し、多くの変数にウェイトをつけて少数の合成変数を作る統計手法である。ビッグデータ分析の現場などにおいて、多変量の情報をできるだけ損なわずに低次元空間に縮約する。多変量データを二次元や三次元データに縮約することで、データ全体の視覚化が可能となり、データのもつ情報を解釈しやすくなる。
「ロジスティック回帰分析」とは多変量解析の一種。線形回帰分析が量的変数を予測するのに対して、ロジスティック回帰分析は質的確率を予測する。「キャンペーン反応率」「特定商品の普及率」などマーケティングの現場で活用されるほか、「土砂災害発生危険基準線の確率」を求めたり、理学療法現場でも活用される。
「ボット(BOT)」とは、人間がコンピュータを操作して行う処理について、人間に代わって特定の命令に従って自動的に実行するアプリケーションプログラムを意味する。主にインターネットにおいて単純な繰り返しタスクを自動で実行するプログラムを指し、ボットによるタスク実行速度は人間が手動で行う場合に比べて遥かに高速に実行される。


2021/03/04 セキュリティDAYS Keyspider資料
本資料を見るには次の画面でアンケートに回答していただく必要があります。


Analytics News ACCESS RANKING








